

The 21st-century businesses are high-end hiring the data scientist. If you would like to get in the flow, utilize these new and highly available opportunities to make sure you have data Science and BA certification to go ahead. There is much data scientists can do in solving intricate business challenges by creating machine learning algorithms. Such as:
● Improve your ability to predict fraud.
● Determine the motivations and preferences of consumers at a granular level. As a result, this promotes brand awareness, lowers financial burdens, and increases revenue margins.
● Forecast future customer demand to ensure optimal inventory deployment.
● Customize the customer experience.
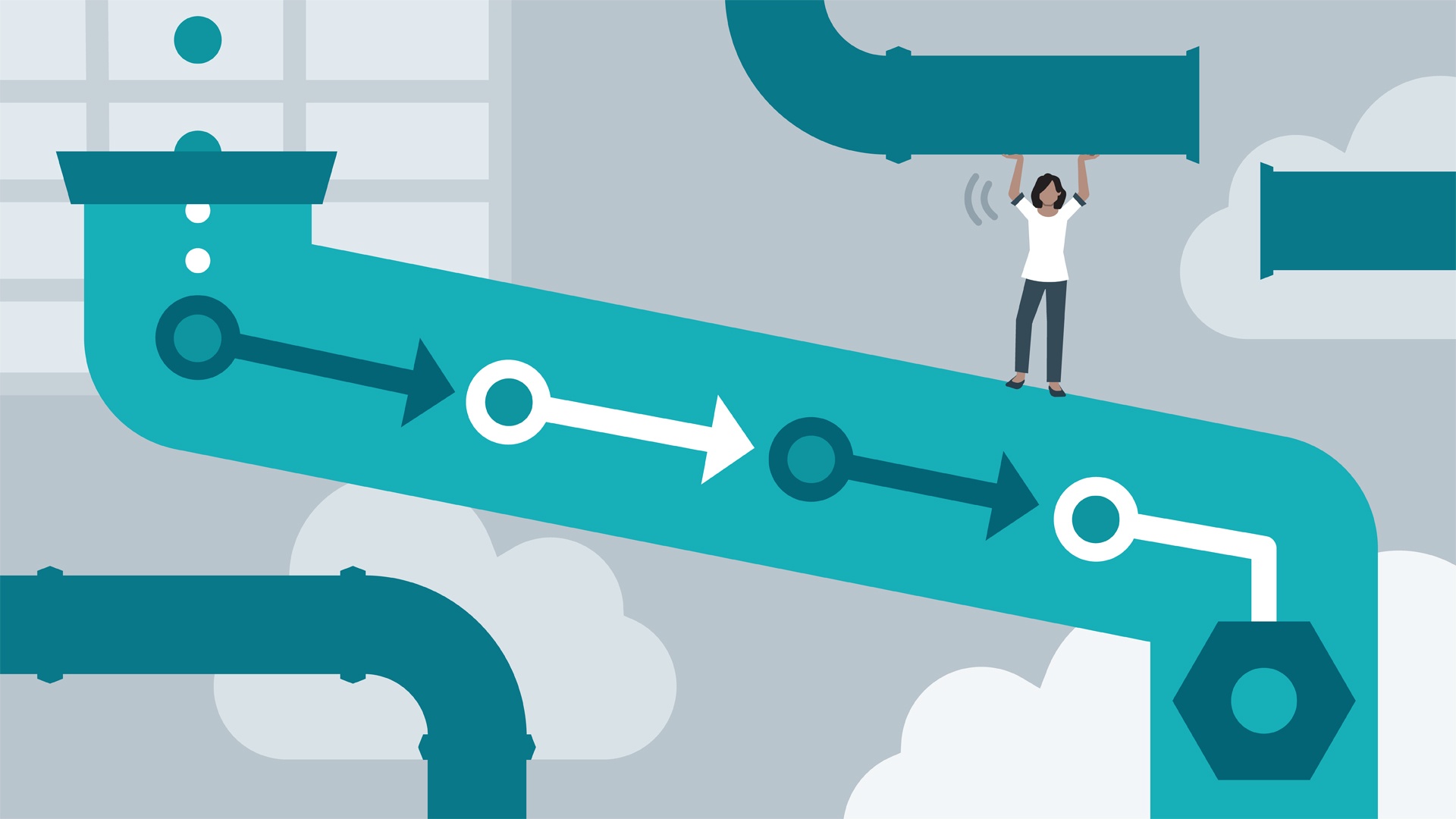
A data pipeline is simply a series of steps that transports raw data from a source to a destination. The destination is the location where the data is analyzed to gain business insights.
Transformation logic is applied to data during this journey from the source to the destination to prepare it for analysis. These steps are learned by enrolling in a PGP in Data Science or Data science and BA certifications.
What is the Usage of Data Pipeline?
Because of the proliferation of cloud computing, a modern enterprise employs a suite of apps to perform various functions. The marketing team may use a combination of HubSpot and Marketo for marketing automation, the sales team may use Salesforce to manage leads, and the product team may store customer insights in MongoDB. As a result, data is fragmented across different tools, resulting in data silos.
Data silos can make even simple business insights, such as your most profitable market, difficult to obtain. Even if you manage to manually collect data from various sources and consolidate it into an Excel sheet for analysis, you may encounter errors such as data redundancy.
Furthermore, the amount of effort required to do it manually is inversely proportional to the complexity of your IT infrastructure. When real-time data, such as streaming data, is added, the problem becomes exponentially more complex. Furthermore, the effort required to do it manually is inversely proportional to the complexity of your IT infrastructure.
When you add data from real-time sources, such as streaming data, the problem becomes exponentially more complex. Data pipelines enable quick data analysis for business insights by consolidating data from all of your disparate sources into one common destination.
They also ensure consistent data quality, which is critical for accurate business insights. But doing all these needs Data Science certifications to become a pro.
What are the Types of Data Passes through the Data Pipeline?
In general, two types of data pass through a data pipeline:
● Structured data is data that can be saved and retrieved in a consistent format. Device-specific statistics, email addresses, locations, phone numbers, banking information, and IP addresses are included.
● Unstructured data is a type of data that is difficult to track. Unstructured data includes email content, social media comments, mobile phone searches, images, and online reviews.
Data pipelines need an excellent dedicated infrastructure while migrating data efficiency, as it will be helpful to extract the business insights from the provided data.
Important Elements of Data Pipeline
Let’s look at the main components of a typical data pipeline to see how it prepares large datasets for analysis. They are as follows:
Source:
A pipeline extracts data from these locations, Relational database management systems (RDBMS), ERPs, CRMs, IoT device sensors, and even social media management tools.
Destination:
This is the data pipeline’s endpoint, where it dumps all of the data it has extracted. The extracted data is usually stored in a data warehouse or a data lake for analysis and extracting business insights. But this isn’t always the case. Data can, for example, be fed directly into data visualization tools for analysis.
Data Flow:
As data travels from source to destination, it changes. Dataflow refers to the movement of data. ETL, or extract, transform, and load, is one of the most common data flow approaches.
Processing:
These are the procedures for extracting data from sources, transforming it, and transporting it to a destination. A data pipeline’s processing component determines how data flow should be implemented. For instance, what extraction process should be used for data ingestion? Batch processing and stream processing are two common methods for extracting data from sources.
Workflow:
Workflow is concerned with the order of jobs in a data pipeline and their interdependence. When a data pipeline runs is determined by dependencies and sequencing. When it comes to data pipeline job assigning, the upstream tasks need to be finished before beginning the downstream jobs.
Monitoring:
A data pipeline must be monitored regularly to ensure data accuracy and loss. A pipeline’s speed and efficiency are also monitored, especially when the data size grows.
Brief about Creating a Data Pipeline
To construct a data pipeline, an organization must first decide on the method of ingestion used to extract data from sources and move it to the destination. Ingestion methods that are commonly used are batch processing and streaming.
Then there’s the decision about which transformation process to use – ELT or ETL – before the data is moved to its final destination. And that’s just the beginning of building a data pipeline. There is a lot more that goes into creating reliable and flexible low-latency data pipelines. And all these can be learned through the PGP in Data Science course.
Do Companies Need a Data Scientist?
There is little agreement on this. Data scientists are in high demand right now, but no one knows what qualifications they should have.
In early 2019, The Open Group (an IT industry consortium) announced three levels of certification for data scientists to fill the void. Candidates must demonstrate knowledge of programming languages, big data infrastructures, machine learning, and AI to earn the certifications.
Data scientists need to build data pipelines in many aspects for organizational benefits. You can even create the data pipelines without much knowledge of coding, making it easier to learn.








